
Description
Ce projet est une interface textuelle qui calcule et affiche des statistiques (nombres de transactions, etc) extraites de la blockchain Bitcoin avec Rust.
Introduction
Ce projet offre la découverte de deux univers ayant récemment émergés : la blockchain Bitcoin, et Rust. La thématique était de manipuler les registres de cette cryptomonnaies en utilisant un langage que nous ne connaissions pas. Ce projet a été fait en collaboration avec des enseignants de Polytech Montpellier.
Fonctionnalités
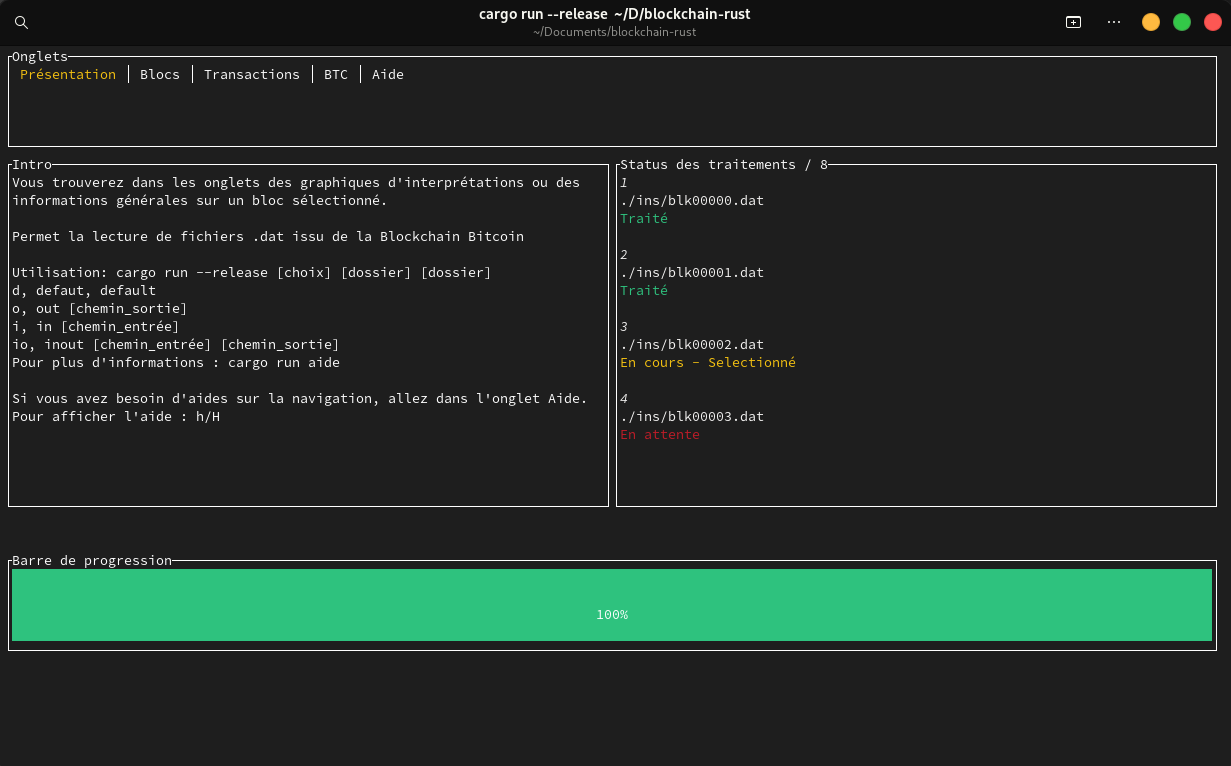
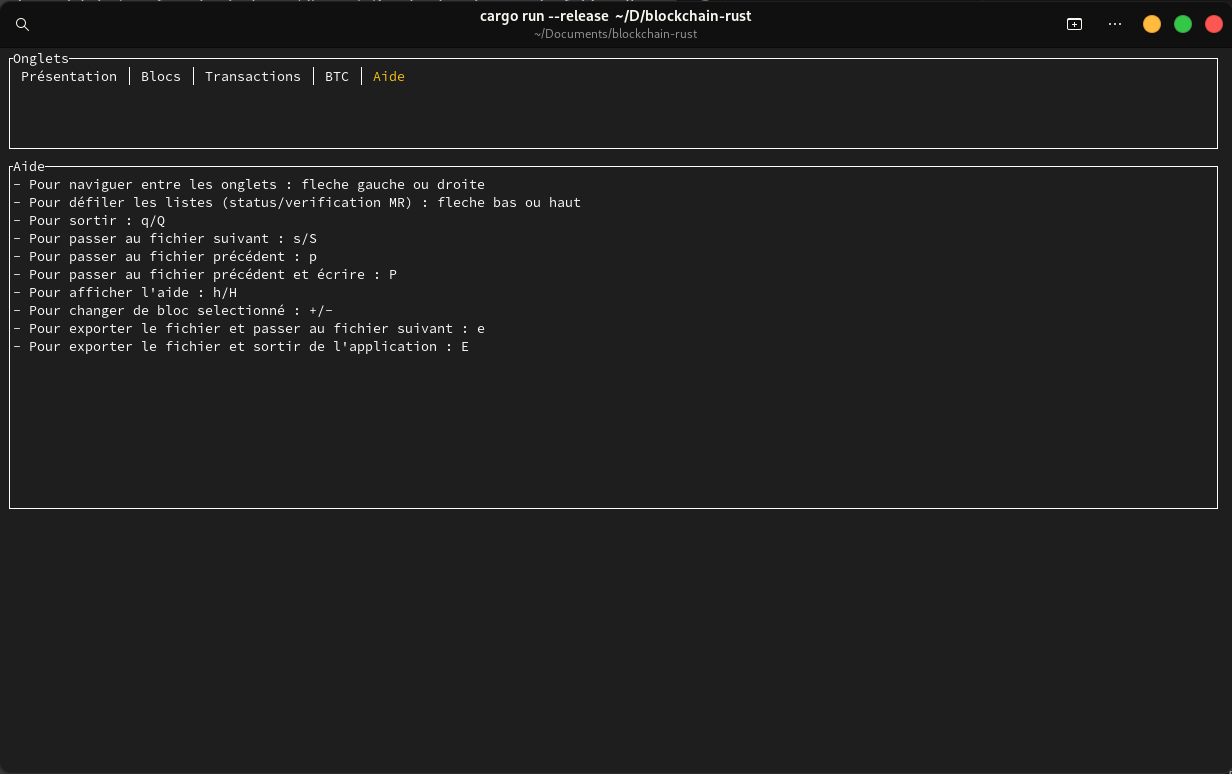
L’interface graphique est accessible depuis un terminal UNIX, Windows, ou même depuis un terminal lancé dans un environnement de développement intégré. L’interface graphique est responsive : elle s’adapte quand l’utilisateur redimensionne la fenêtre. Celle ci est divisée en cinq onglets.
- l’onglet Présentation :
- présente brièvement le programme,
- rappelle les commandes que l’on peut faire pour lancer le programme autrement,
- affiche les touches pour afficher immédiatement l’aide ;
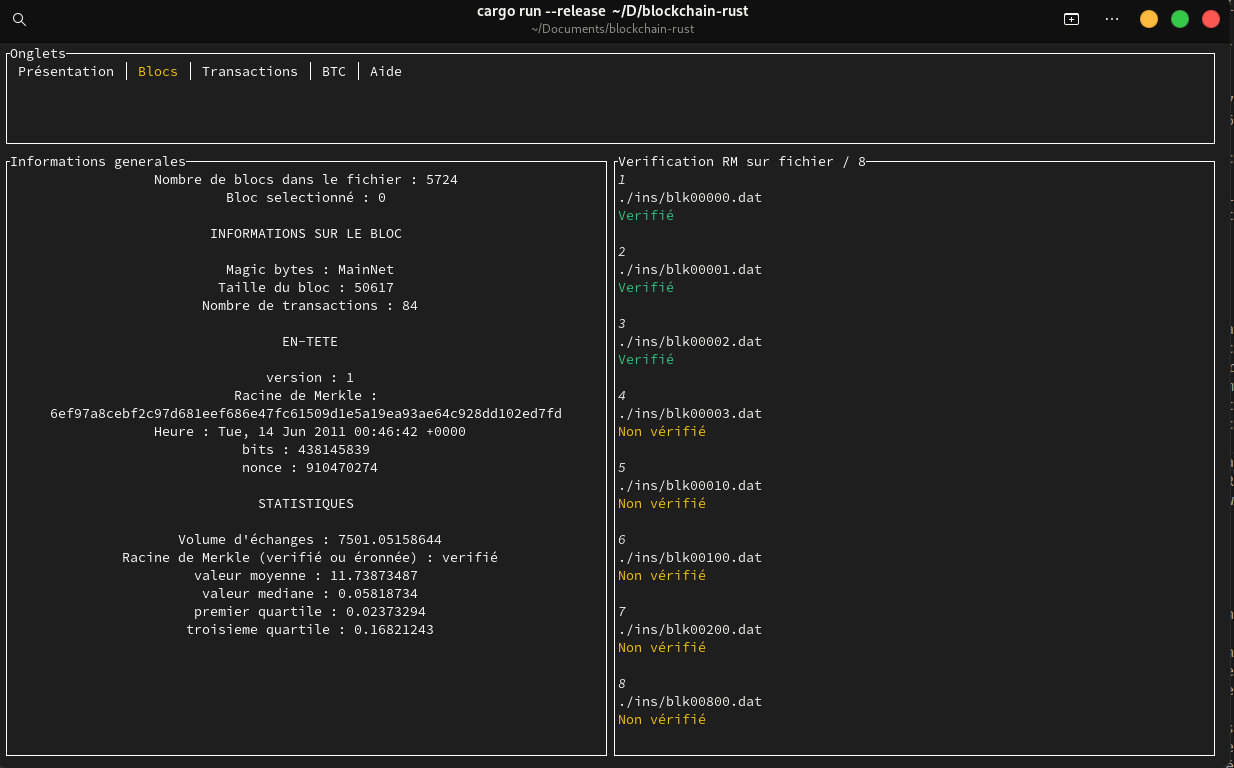
- l’onglet Blocs affiche les informations générales d’un bloc :
- la taille du bloc, le nombre de transactions,
- la version, la racine de Merkle, l’horaire, les bits, le nonce,
- diverses statistiques (le volume d’échanges, la valeur moyenne et médiane, le premier et troisième quartile) ;
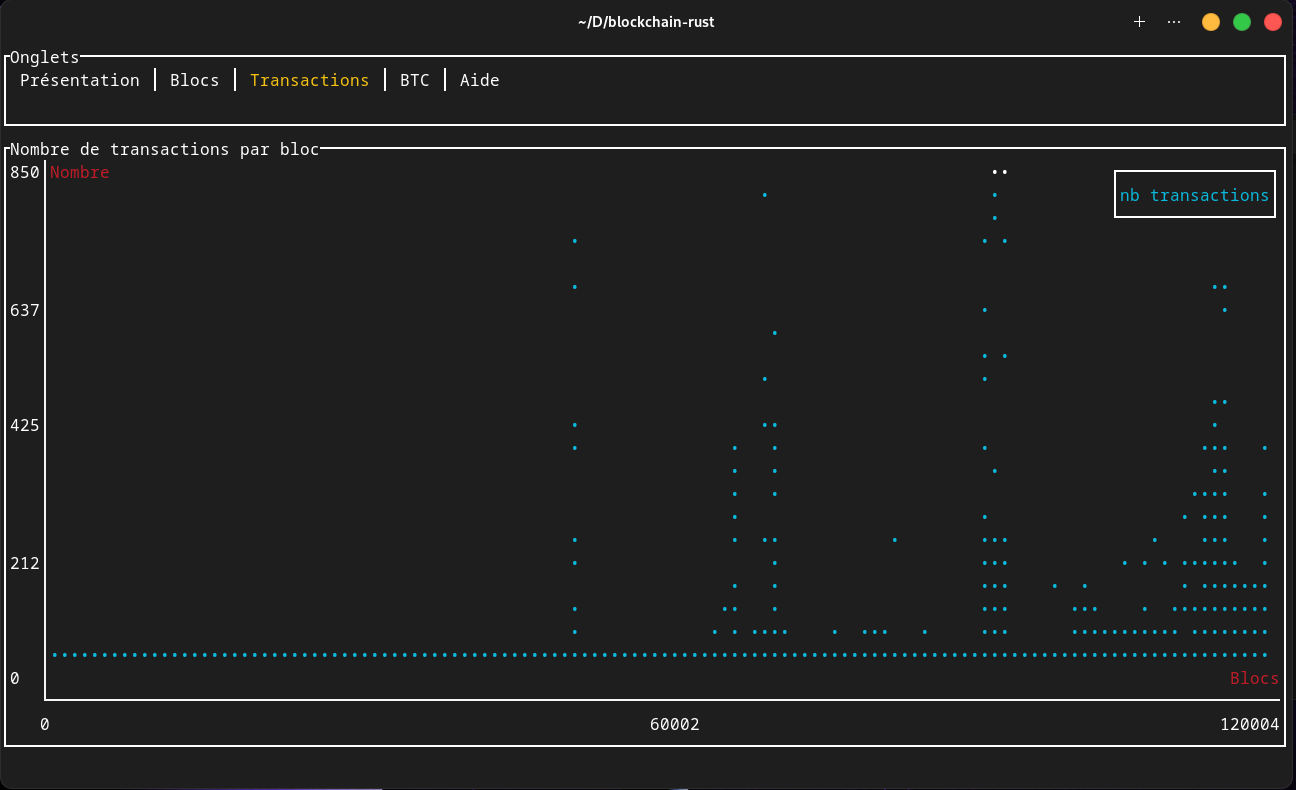
- l’onglet Transactions affiche un graphique du nombre de transactions par bloc,
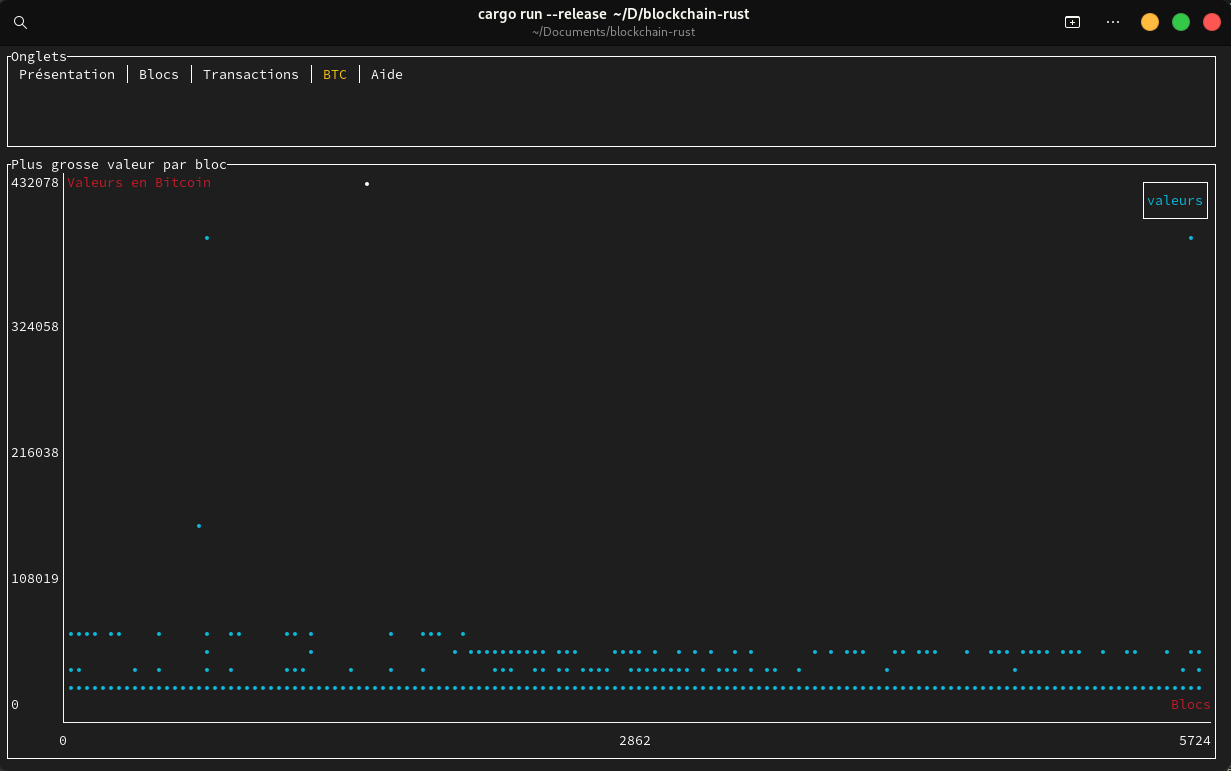
- l’onglet BTC affiche un graphique de la plus grosse valeur par bloc,
- l’onglet Aide explique comment naviguer entre les onglets, et comment accéder aux différentes fonctionnalités.
Nous avons aussi mis en place des barres de progressions sur l’exportation des données, la mise en place des données pour le terminal ainsi que pour le parseur avec le nom spécifique du lieu d’écriture ou de lecture. Au moment de l’écriture nous proposons plusieurs choix à l’utilisateur : json ou txt ou le choix de quitter l’écriture.
Nous avons donc opté pour un nuage de points. Celui-ci permet de voir les résultats sur tous les blocs en même temps. Il y a aussi la présence du repère avec les blocs (abscisses) et le nombre de blocs (ordonnées) ce qui permet d’avoir plus de recul et d’impact sur la totalité des blocs.
Démo
Utilisation du projet
Crates
Nous avons utilisé les crates suivantes :
- chrono : une bibliothèque pour la gestion du temps qui permet d’interpréter l’heure Unix contenue dans l’en-tête des blocs
- crossterm : une bibliothèque pour manipuler un terminal
- hex-string : une structure qui facilite la convertion de vecteurs d’entiers vers des chaînes hexadécimales, et qui est particulièrement utile du fait que la base 16 est largement utilisée dans Bitcoin pour les repré- sentations de clés privées, clés publiques, signatures ou hashs,
- sha2 : une implémentation des fonctions de hachage de la famille SHA-2, qui permet d’utiliser la fonction SHA-256, nécessaire pour obtenir, entre autres, des identifiants de blocs ou de transactions,
- tui-rs : une bibliothèque qui permet de construire des interfaces utilisateur et des tableaux de bord dans un terminal, en les divisant en widgets affichables, et qui permet également de définir et contrôler.
Installations
- cmake
- pkg-config
- libssl
- libfreetype6-dev (Debian)
- libexpat1-dev (Debian) / libexpat
- libxcb-composite0-dev (Debian) / libxcb (Arch Linux)
Debian
sudo apt install cmake
sudo apt install pkg-config libasound2-dev libssl-dev cmake libfreetype6-dev libexpat1-dev libxcb-composite0-dev
Arch Linux
sudo pacman -S cmake pkg-config libexpat libxcb
Lancements
Les fichiers blk.dat doivent être placés dans un dossier ./ins, et les fichiers d’exportation sont placés dans un dossier ./outs dans le projet. Il est possible de choisir le dossier contenant les fichiers à lire, le dossier contenant les fichiers à exporter, ou les deux à la fois, en lançant le programme ainsi :
cargo run --release i ./dossier_à_lire/
cargo run --release o ./dossier_où_exporter/
cargo run --release io ./dossier_à_lire/ ./dossier_où_exporter/
Implémentation
Cahier des charges
Les fonctionnalités qui étaient à implémenter rentrent dans trois catégories
-
Désérialiser les données contenues dans les fichiers blk.dat :
- Lire les métadonnées de l’en-tête (version, hash du bloc précédent, etc.),
- Lire les transactions,
- Reconstruire l’arbre de Merkle ;
-
Analyser les données :
- Compter le nombre de transactions contenues dans un bloc,
- Extraire les adresses,
- Rechercher la plus grande somme transférée, calculer la somme moyenne transférée en fonction d’une période, etc. ;
-
Exporter les données via un affichage ou dans un fichier
Approche
Pour réaliser ce projet, nous avons tout d’abord mis en place un parseur capable de lire des fichiers blk.dat, les uns après les autres, de délimiter les différents champs contenus dans ce fichier, puis de stocker les données en mémoire, dans des structures au format approprié. Nous vérifions ensuite l’intégrité des données par le calcul de la racine de Merkle. Par la suite, l’analyse des données est faite depuis ces structures stockées en mémoire. Finalement, l’utilisateur peut visionner les données depuis une interface graphique intégrée au terminal.
Parseur
Le parseur, notre module le plus important. Dans un premier temps, l’entièreté du fichier blk.dat est placée telle quelle dans un tampon en mémoire, ce qui offre plus de liberté pour déplacer un curseur en fonction d’un nombre variable d’octets. Puis, le module analyse octet par octet le tampon détermine sa taille, ses transactions, et enfin le stocke en mémoire dans une structure adaptée.
Un fichier blk.dat est constitué de blocs mis les uns à la suite des autres. Chaque bloc est constitué de plusieurs champs de tailles et de types différents. Certains champs ont une taille fixe, comme les bits magiques qui annoncent le début d’un bloc et le type du réseau qui a été employé. Ses quatre octets sont toujours les mêmes parmi « f9beb4d9 », « 0b110907 » et « fabfb5da ». Pour obtenir les bits magiques, le parseur lit simplement les quatre premiers octets. En revanche, certains champs n’ont pas de taille fixe. C’est le cas du champs « Input Count » qui indique le nombre de transactions à venir. Ce nombre peut être un, comme mille. La taille du nombre de transactions étant variable, le parseur ne devra donc pas lire systématiquement le même nombre d’octets afin de le déterminer. Pour qu’il soit possible de deviner sa taille, l’« Input Count » utilise un système de préfixe. Si la valeur du premier octet (le préfixe) est supérieure à 0xfc, il faut se reporter à ce tableau :
Préfixe Exemple Description
| Préfixe | Exemple | Description |
|---|---|---|
| ≤ 0xfc | 12 | Lire zéro octet de plus |
| ≤ 0xfd | fd1234 | Lire deux octets de plus |
| ≤ 0xfe | fe12345678 | Lire quatre octets de plus |
| ≤ 0xff | ff 1234567890abcdef | Lire huit octets de plus |
Le module lecture_frac gère également l’exportation des données vers des fichiers. Il permet d’exporter l’entièreté d’un fichier blk.dat vers un fichier json, en rendant ses données facilement compréhensibles, ou encore d’exporter toutes les adresses présentes depuis un fichier blk.dat vers un fichier txt.
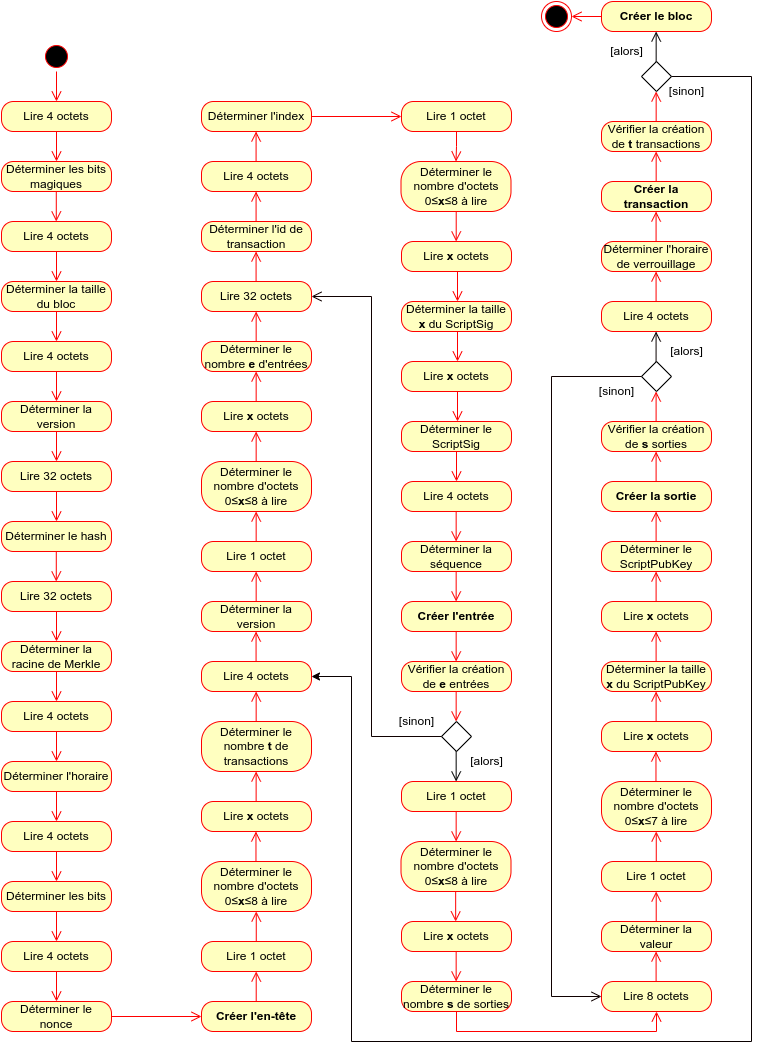
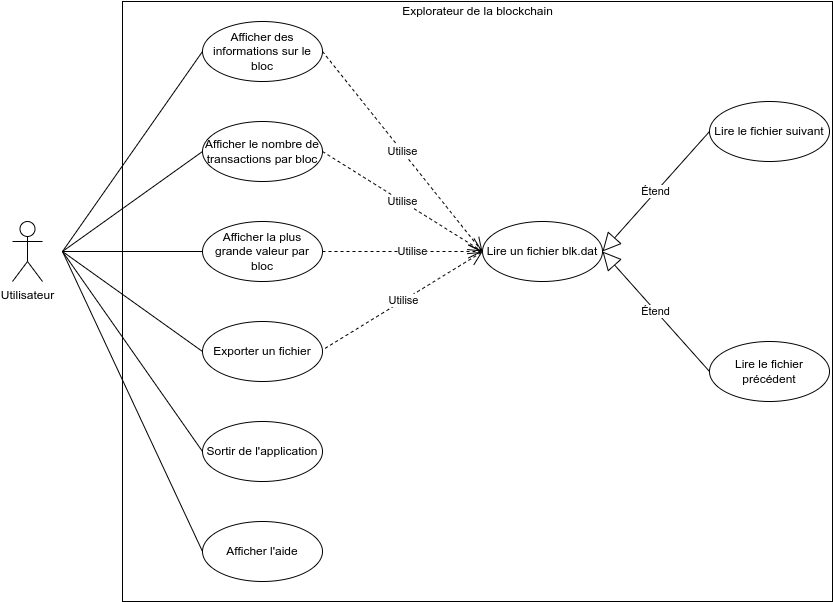
Autres modules
- Le module conversions contient une fonction de conversion entre satoshis et bitcoins, ainsi qu’une fonction qui permet un affichage agréable de l’horaire.
- Le module merkle_tree contient les fonctions nécessaires au calcul de la racine de Merkle, et à l’affichage de l’arbre reconstitué.
- Le module recherches offre plusieurs fonctions de recherche : une fonction qui recherche la plus grande somme transférée dans tout le fichier, une qui fait la même recherche mais pour chaque bloc, ainsi qu’une fonction qui calcule la somme des bitcoins échangés au cours d’un même journée passée en paramètre.
- Le module tris permet de trier en O(n log n) l’ensemble des blocs selon l’horaire qu’ils contiennent. Rappelons que lorsqu’on télécharge les blocs depuis un réseau Bitcoin, il arrive que certains blocs soient téléchargés dans le désordre.
- Enfin, le module Calculs contient les fonctions qui permettent l’extraction des clefs publiques, de leurs hashs, et des adresses.
Multithreading
Après la première mise en place du parseur, ce dernier était très lent. L’outil était également ralenti par le calcul de la racine de Merkle. Nous avons pu apporter des optimisations grâce à la mise en place de threads dans le module lecture_frac et dans le module merkle_tree.
L’idée ici est qu’un thread travaille sur un certain nombre de blocs. Il faut donc compter le nombre de blocs du fichier, ainsi que leur longueur. Comme un bloc commence par les bits magiques, suivis de sa taille, il suffit de lire les huit premiers octets, et de déplacer le curseur en l’incrémentant avec la taille extraite. Cette dernière est également stockée dans un tableau dynamique d’entier. Ensuite, il faut vérifier que le nombre de threads est bien supérieur au nombre de blocs, afin de voir s’il y a une utilité de threader la lecture du fichier. Pour cela, on fait la division entre le nombre de blocs dans un fichier, et le nombre de threads qu’on veut donner. Finalement, il devient possible de répartir le nombre de blocs par threads.